SEOにも配慮したHTML遅延読み込み Hybrid Include で Core Web Vitals を改善する試み
小さいHTMLは正義 HTMLはWebページ全体(数mb)から見ると小さなリソー...

小さいHTMLは正義
HTMLはWebページ全体(数mb)から見ると小さなリソース(数十Kb)なので、10kbや20kb増えたところで大した影響はないだろうと思われがちです。
確かに10kbや20kbのダウンロード時間は些末な差で、昨今はスマホも高性能です。しかしHTMLサイズが大きい場合(≒DOMツリーの巨大化)、初期のレンダリング以後も意外と繰り返し発生するレイアウト計算、この負担はボディブローのように効いてきます。
Core Web VitalsやPageSpeed Insightsのスコア改善の観点からは、小さいHTMLは正義です。
遅延読み込みによるHTMLの軽量化
とはいえ伝えたいことがたくさんあるページでは、自ずとHTMLが大きくなります。
ページやサイトの設計から見直すのは大変ですが、比較的、楽に対処する方法があります。それがHTMLの遅延読み込みです。
初めは数画面分の小さなHTMLを配信し、小さなページとして速やかに表示を完了させます。もしユーザーがスクロールしてページを読む意思を示したら、ページの下部をJavaScriptの処理により読み込む、という仕組みです。
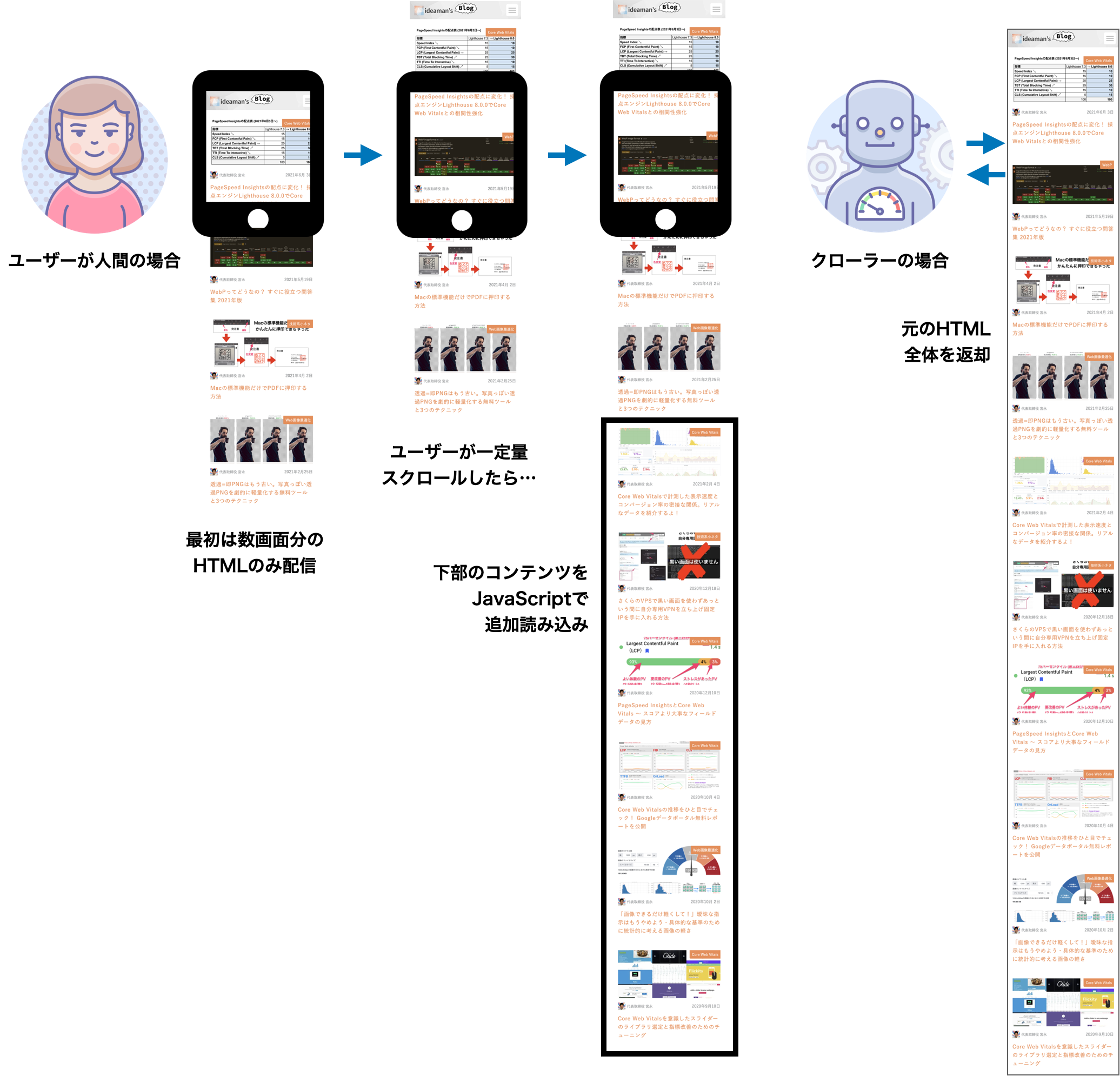
実際のところユーザーはほとんどスクロールせず離脱する可能性があります。いや、むしろその方が多いと思うべきでしょう。にもかからわず、初めから全リソースを配信してパフォーマンスを下げてしまうのは投機的に下策です。
しかしこの方法には、検索エンジン対策としてページ下部がインデックスされない懸念もあります。
そこでクローラーからのアクセスに対しては、サーバー側で元の大きなHTMLに合成して、元の巨大なHTMLを静的に配信することでその懸念を解消します。
つまりはダイナミックレンダリング
この手法は、Googleが言及する ダイナミックレンダリング に相当します。
クローラーには通常と異なるコンテンツをインデックスさせるクローキングはペナルティの対象ですが、
ダイナミック レンダリングで同様のコンテンツを生成する限り、Googlebot はダイナミック レンダリングをクローキングとは見なしません。
...に基づき、この方法はクローキングには該当しません。
人間のユーザーにはJavaScriptで下部コンテンツをincludeし、クローラーにはサーバーサイドでincludeすることから、Hybrid Includeと名付けました(すでにありそうなアイデアですが、例を見つけられなかったのでひとまず)。
Hybrid IncludeでCore Web Vitalsが改善されるか?
ここで実装例と、PageSpeed Insightsの計測結果を紹介します。
大きなHTMLのサンプル
次のページは、このブログの全記事を一覧表示した大きなHTMLのサンプルです。
A. このブログの全記事を一覧表示したサンプルページ (HTML 38.6kb / GZIP)
Hybrid Includeを実装したサンプル
次のページは、Hybrid Includeを実装したサンプルです。初期段階のHTMLは10記事分のみ配信し、300ピクセル以上スクロールするとその下のコンテンツを展開します。
B. Hybrid Includeで初期HTMLの軽量化を図ったページ (HTML 5.2kb / GZIP)
HTMLのデータ量に33kbほどの差があります。
PageSpeed Insightsのスコアが9ポイント改善
PageSpeed Insightsでこれらのページを計測したところ、約10ポイントの改善がみられました。
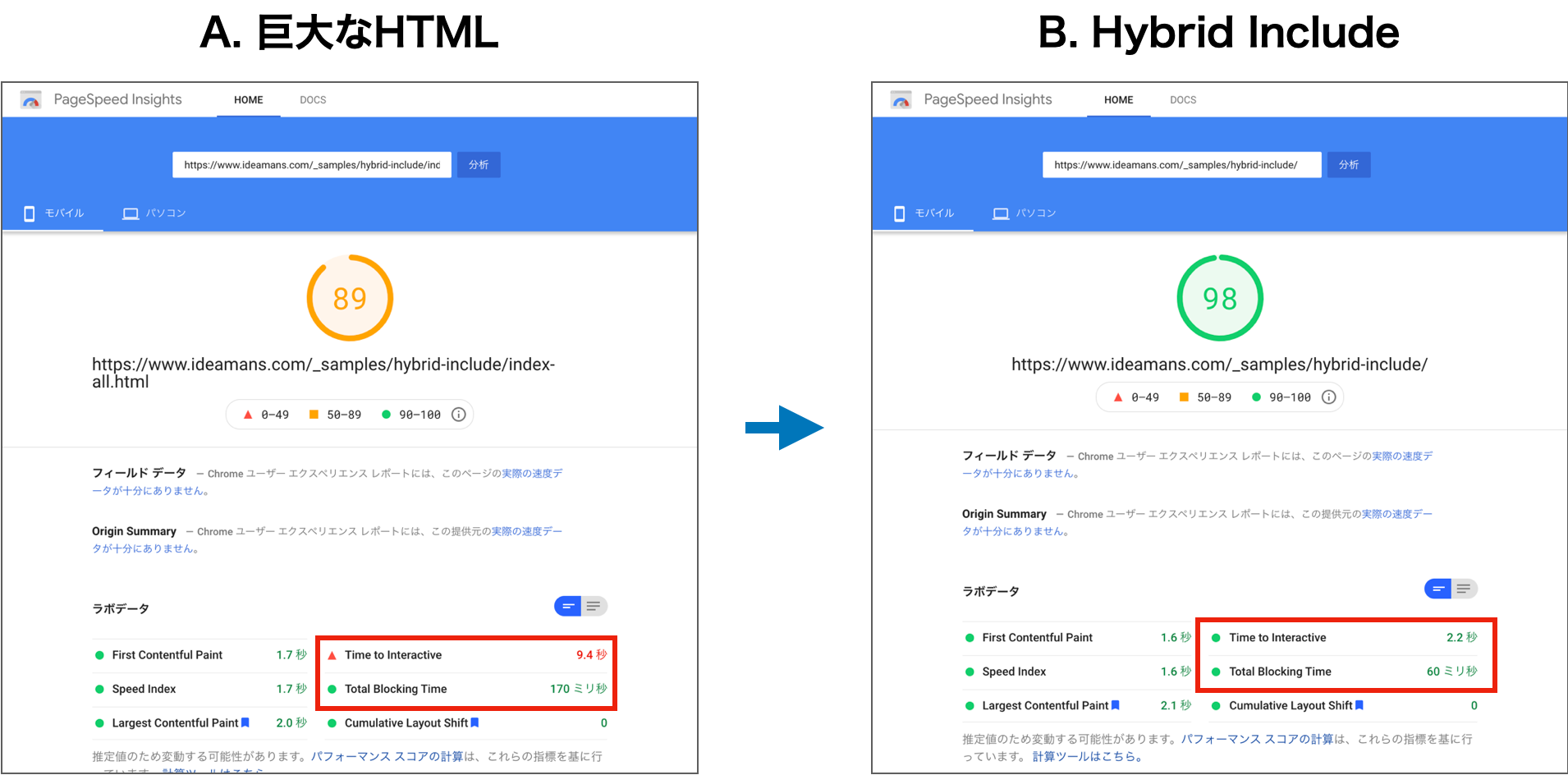
個別の指標としては、Time To InteractiveとTotal Blocking Timeに改善が見られます。Core Web Vitalsで言えば、FID(First Input Delay)の改善を見込める変化です。
PHPを例とした実装方法
Hybrid IncludeにはCore Web Vitalsに対する効果が見込めるとわかりました。
次はPHPを例とした具体的な実装方法です。
1. 遅延読み込みする部分HTMLの切り出し
はじめに、遅延読み込みする部分HTMLを別ファイルとして切り出します。例えば元のHTMLが次の構造であれば、
<html>
<body>
<div>
<div>ページ上部</div>
</div>
<div>
<div>ページ下部</div>
</div>
</body>
</html>
以下の部分を次のファイルindex-includee.html として保存します。
<div>ページ下部</div>
2. 読み込み先の目印となるid属性
部分HTMLを別ファイルへ切り出した代わりに、JavaScriptによる遅延読み込みで展開する先の目印をid属性で示します(例: hybrid-includer)。
<div>
<div>ページ下部</div>
</div>
↓
<div id="hybrid-includer">
</div>
3. Hybird Includeの実装
展開先div#hybrid-includer内に次のPHPコードを記述します。コードの意図についてはコメントで記載しました。
<div id="hybrid-includer">
<?php
// 部分HTMLを切り出したファイル名
$includee = 'index-includee.html';
// URLパラメータincludeが指定されているか、User-AgentがGooglebotまたはbingbotを含む場合はPHPでinclude
if (preg_match('/Googlebot|bingbot/', $_SERVER['HTTP_USER_AGENT']) || isset($_GET['include'])) {
include($includee);
} else {
?>
<script>
(function() {
var includeIfOver = 300 // 遅延読み込みを開始するスクロール量
var includee = '<?php echo $includee ?>'
window.addEventListener('scroll', function once(e) {
if (window.scrollY < includeIfOver) return
// このイベントハンドラは不要になるので除去
window.removeEventListener('scroll', once)
// includeeを読み込んで#hybrid-includerに展開(モダンブラウザ対象であればfetchも可)
var xhr = new XMLHttpRequest()
xhr.open('GET', includee, true)
xhr.onload = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
document.getElementById('hybrid-includer').innerHTML = xhr.responseText
}
}
xhr.send(null)
})
})()
</script>
<?php
}
?>
</div>
リクエストヘッダUser-AgentがGooglebotまたはbingbotを含む場合(あるいはデバッグ用途でURLパラメータincludeが指定された場合)は、PHPとして要素div#hybrid-includerの内部に部分HTMLをincludeして展開し、クライアントに配信します。
逆にUser-Agentが条件に合致せず、一般ユーザーからのアクセスと思われる場合は、一定のスクロール量に応じて切り出した部分HTMLをJavaScriptで読み込み、要素div#hybrid-includerの内部にその内容を展開します。
この仕組により、人間の実ユーザー向けには段階的なコンテンツ配信でページ表示のスタートダッシュを高速化しつつ、クローラー向けには静的HTMLとしてコンテンツ全量を配信してSEO上の懸念の解消を図ることができます。